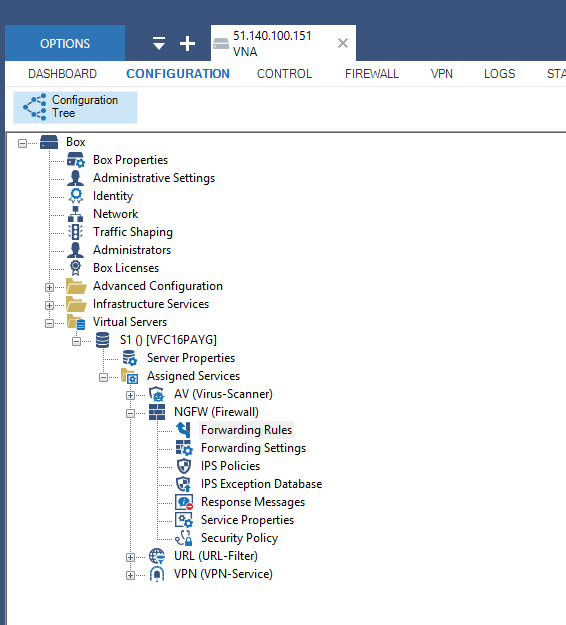
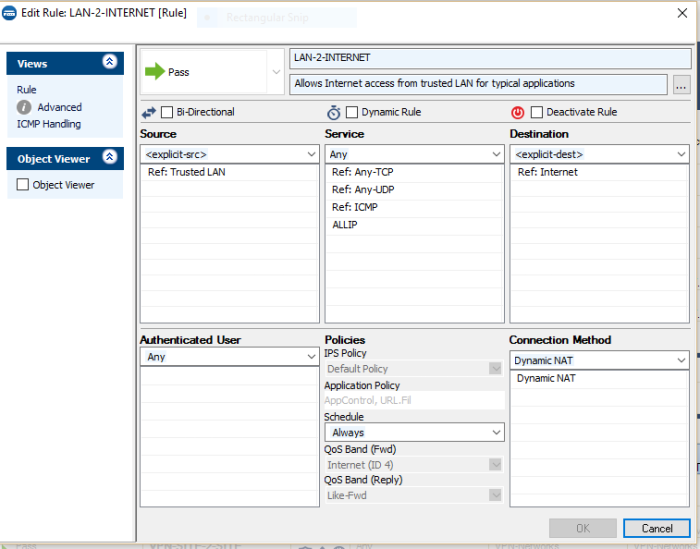
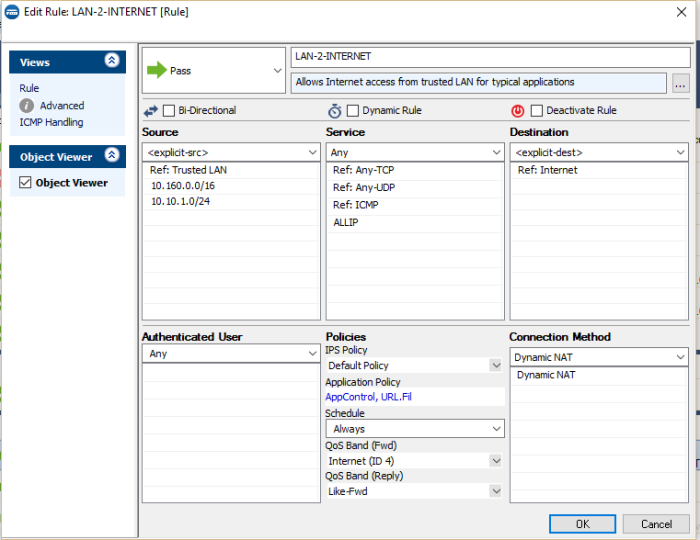
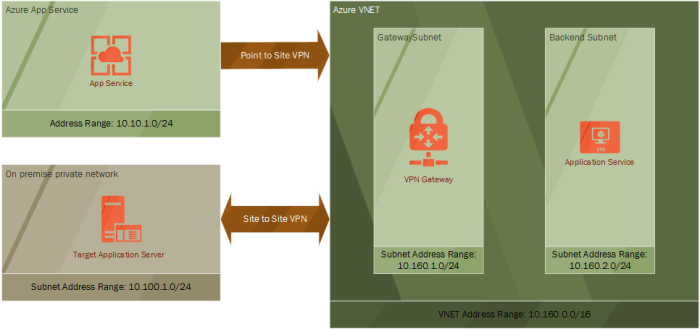
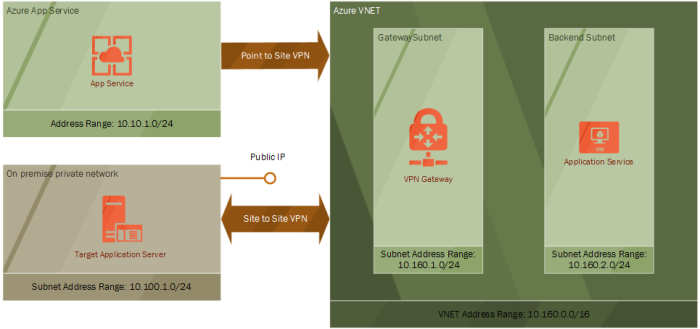
I mentioned last time that to test out the system that has been building up over the last few posts you need a simulated on premise network. I briefly outlined that is was possible to copy many of the steps taken to build up cloud network to act as an on-premise network.
However, when I did this for real I was learning Amazon Web Services (AWS). So, this was the perfect opportunity to test out what I had learnt. The rest of the post is a walk-through I what I set up.
I’m not going to cover how to set up a Amazon account so I assume you have already done this. Amazon is slightly less forgiving when it comes to accruing costs so it is your responsibly to ensure that you choose free or cheap resources and that you delete things when you are done.
Secondly the walk-through builds up an IaaS based implement. The reason I do this is that it is closer to what you’ll find when integrating with an on-premise network for real. It is often useful to be able to have enough of understanding of the moving parts so that you can have productive conversations with the engineers working with the on-premise systems whose help you’ll need.
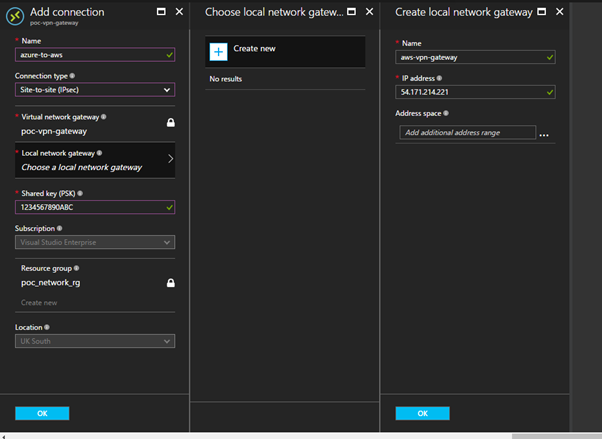
This walk-through will configure an EC2 instance running Windows Server on a VPC in AWS. The Windows Server will be running Remote Access Services (RAS) configured to act as an VPN endpoint. I use a T2 Micro sized EC2 instance to keep within the Free Tier in AWS. Before you can complete these steps you need two things from Azure, that this the Public IP address of your VPN Gateway and the shared secret you used when setup the Site to Site VPN in Azure.
AWS Configuration
- Log into the AWS and open up the VPC options
- Use the “Start VPC Wizard” and create a “VPC with a Single Public Subnet”. Note that a public rather than private subnet is used to keep the network configure simple and to allow RDP access to the EC2 instance over the Internet. Once the VPN is set up communication will be via a private IP address.
- For the IP4 CIDR block use 10.100.1.0/24. Give the VPC a name and use the same address range for the Public Subnet’s address range. The rest of the options can be left as their defaults.
Notice how similar this is to setting up an Azure VNET. AWS VPCs and Azure VNETs are equivalent. What the AWS VPC wizard does in the background is create an Internet Gateway and network routing which allows traffic from this subnet out on to the Internet.
Using the same address range for the VPC and the subnet is not something you’d do for real but it is enough for this demo.
- Open up the EC2 page and select Launch Instance
- From the list of Amazon Machine Images (AMI) select Microsoft Windows Server 2016 Base
- On the instance type page ensure t2 micro is selected, and click “Next: Configure Instance Details”
- On the Configure Instance Details page ensure that you change the network and subnet to the one created in Step 3. You also want to set Auto Assign Public IP to Enabled so we have the ability to RDP to the instance over the Internet. Everything else can be left at their default settings.
- Remember to either create or use an existing key pair in order to be able to get the EC2 instance’s Admin password.
It will take a few minutes for the instance to start and be at a state where you’ll be able to obtain the admin password. Once you have the password you’ll be able to RDP into it using the public IP it was assigned at startup
- Your EC2 instance will be acting as a network gateway which will allow network traffic destine for other resources to flow through it. AWS doesn’t allow that by default, but it can be setup by disabling source/destination checking.
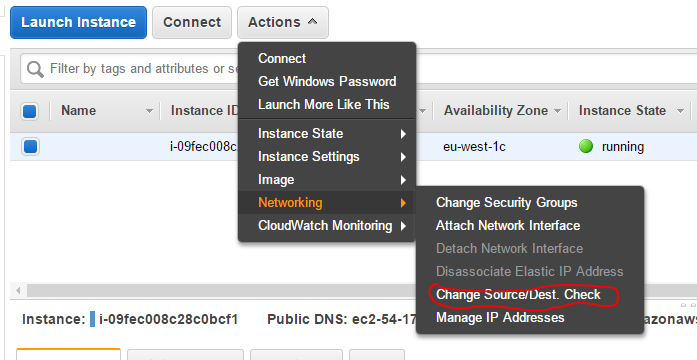
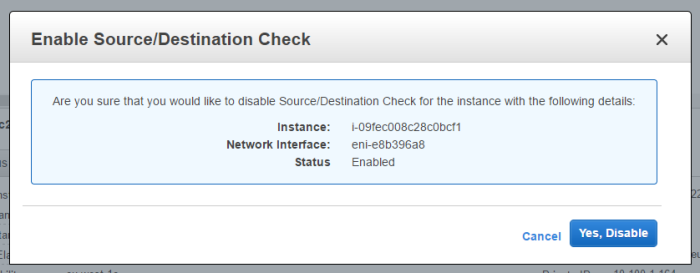
- Open RDP and connect to your windows EC2 instance as Administrator
- There is a script available here at that will install and configure RRAS on your server. It mentions Windows Server 2012 but it also works Windows Server 2016. It requires a few changes for the demo setup, so the updated script is included below.
# Windows Azure Virtual Network
# This configuration template applies to Microsoft RRAS running on Windows Server 2012 R2.
# It configures an IPSec VPN tunnel connecting your on-premise VPN device with the Azure gateway.
# !!! Please notice that we have the following restrictions in our support for RRAS:
# !!! 1. Only IKEv2 is currently supported
# !!! 2. Only route-based VPN configuration is supported.
# !!! 3. Admin priveleges are required in order to run this script
Function Invoke-WindowsApi(
[string] $dllName,
[Type] $returnType,
[string] $methodName,
[Type[]] $parameterTypes,
[Object[]] $parameters
)
{
## Begin to build the dynamic assembly
$domain = [AppDomain]::CurrentDomain
$name = New-Object Reflection.AssemblyName 'PInvokeAssembly'
$assembly = $domain.DefineDynamicAssembly($name, 'Run')
$module = $assembly.DefineDynamicModule('PInvokeModule')
$type = $module.DefineType('PInvokeType', "Public,BeforeFieldInit")
$inputParameters = @()
for($counter = 1; $counter -le $parameterTypes.Length; $counter++)
{
$inputParameters += $parameters[$counter - 1]
}
$method = $type.DefineMethod($methodName, Public,HideBySig,Static,PinvokeImpl',$returnType, $parameterTypes)
## Apply the P/Invoke constructor
$ctor = [Runtime.InteropServices.DllImportAttribute].GetConstructor([string])
$attr = New-Object Reflection.Emit.CustomAttributeBuilder $ctor, $dllName
$method.SetCustomAttribute($attr)
## Create the temporary type, and invoke the method.
$realType = $type.CreateType()
$ret = $realType.InvokeMember($methodName, 'Public,Static,InvokeMethod', $null, $null, $inputParameters)
return $ret
}
Function Set-PrivateProfileString(
$file,
$category,
$key,
$value)
{
## Prepare the parameter types and parameter values for the Invoke-WindowsApi script
$parameterTypes = [string], [string], [string], [string]
$parameters = [string] $category, [string] $key, [string] $value, [string] $file
## Invoke the API
[void] (Invoke-WindowsApi "kernel32.dll" ([UInt32]) "WritePrivateProfileString" $parameterTypes $parameters)
}
# Install RRAS role
Import-Module ServerManager
Install-WindowsFeature RemoteAccess -IncludeManagementTools
Add-WindowsFeature -name Routing -IncludeManagementTools
# !!! NOTE: A reboot of the machine might be required here after which the script can be executed again.
# Install S2S VPN
Import-Module RemoteAccess
if ((Get-RemoteAccess).VpnS2SStatus -ne "Installed")
{
Install-RemoteAccess -VpnType VpnS2S
}
# Add and configure S2S VPN interface
Add-VpnS2SInterface -Protocol IKEv2 -AuthenticationMethod PSKOnly -NumberOfTries 3 -ResponderAuthenticationMethod PSKOnly -Name 51.140.107.124 -Destination 51.140.107.124 -IPv4Subnet @("10.160.1.0/24:100", "10.160.2.0/24:100", "10.10.1.0/24:100") -SharedSecret 1234567890ABC
Set-VpnServerIPsecConfiguration -EncryptionType MaximumEncryption
Set-VpnS2Sinterface -Name 51.140.107.124 -InitiateConfigPayload $false -Force
# Set S2S VPN connection to be persistent by editing the router.pbk file (required admin priveleges)
Set-PrivateProfileString $env:windir\System32\ras\router.pbk "51.140.107.124" "IdleDisconnectSeconds" "0"
Set-PrivateProfileString $env:windir\System32\ras\router.pbk "51.140.107.124" "RedialOnLinkFailure" "1"
# Restart the RRAS service
Restart-Service RemoteAccess
# Dial-in to Azure gateway
Connect-VpnS2SInterface -Name 51.140.107.124
It is surprisingly difficult to highlight within a code block in WordPress so review the IP addresses in the calls Add-VpnS2SInterface, Set-VpnS2Sinterface and Set-PrivateProfileString carefully.
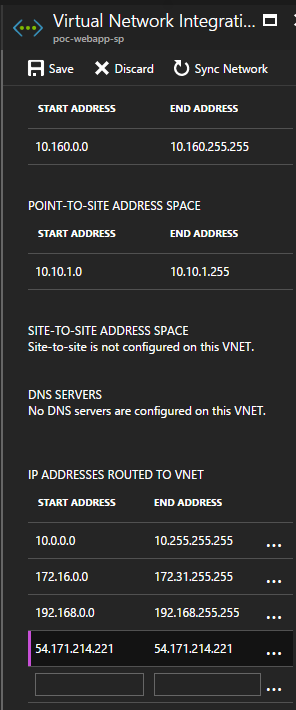
This script installs the RRAS feature. It then configures an interface which will allow traffic into the VPN. You need to define where the VPN will connect to, which is the Public IP address of your Virtual Network Gateway in Azure. You then need to define all the subnets that can be routed to via the VPN. In this case, we define the address range for the Gateway and Backend subnets. We also define the address pool for the Point to Site VPN. This will allow traffic that entered the on premise network from the App Services to flow back again. Finally, we use the same shared secret that set up on the Azure side.
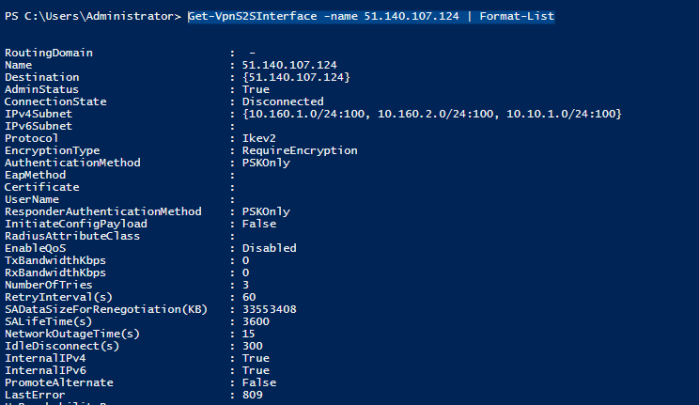
- Once the script has run you can confirms its status via the powershell command
Get-VpnS2SInterface -name 51.140.107.124 | Format-List. The result should be something like this. Note that the ConnectionState will remind Disconnected until the Azure side is setup.
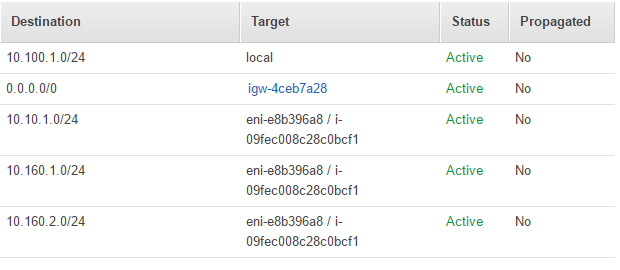
- You’ll need to set up routing rules which allows network traffic to flow correctly from the AWS VPC through the VPN connection. Open up the Route Table associated with the subnet you created and add the following routes. The routes tells AWS VPC to route traffic destine to the Azure VNET and App Services sitting at the end of the Point to Site VPN, through the EC2 instance running the AWS side of the VPN Gateway.
If you attempt to simulate an on-premise network in Azure by creating another VNET and VPN gateway and connecting that to the other side of the Site to Site VPN you also need equivalent routes.
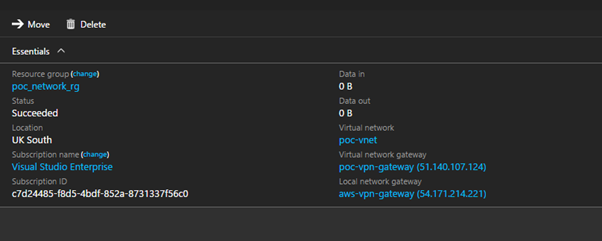
At this point if you have completed the Site to Site VPN configuration on the Azure side you should be set. Check that the Azure side VPN connection is reporting Connected and rerun Get-VpnS2SInterface -name 51.140.107.124 to see if the AWS side is happy.

Sometimes the RRAS service does not start correctly, so if you are having problems to run the command Connect-VpnS2SInterface -Name 51.140.107.124.